Benchmarking LLMs using Wordle
LLM benchmarks are sort of an odd thing. Every time a new model is released these fancy graphs saying they are X% better in Y category and compare themselves against each other. Some times they line up to real world usage, but most of the time you should probably just ignore them.
(Including this one! probably)
Introducing Wordle Bench. A simple benchmark on how well a model can solve wordle.
Why?
Wordle is a game that consists of some strategy and logic. The LLM needs to keep track of guesses, feedback and analyze the information to make informed guesses. This makes it a good benchmark for evaluating the reasoning capabilities of LLMs.
Results
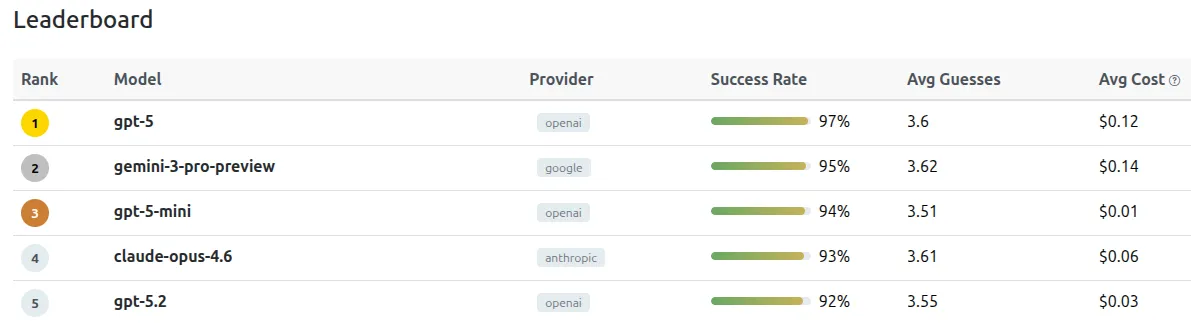
You can see the full results at https://www.wordlebench.com
At the top is gpt-5 with a 97% solve rate. A super surprising ranking is gpt-5-mini at #3 and a 94% solve rate. This seems to be the best price/performance model out of the list. The top open source is kimi k2.5 at 86% solve rate.
I think these are some interesting results to start. I'll continue to publish these as new models come out.
I have the code over on Github: https://github.com/abronte/wordlebench